Бесплатно игровая валюта для более 200 игр, а так же ОКи
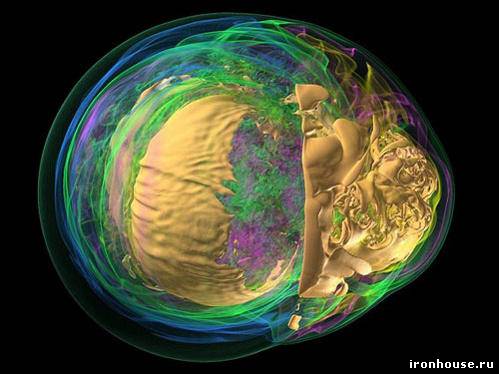 До появления специализированных графических вычислительных чипов пионеры в области визуализации использовали мультиядерные суперкомпьютеры, чтобы представить данные в трехмерном виде. По состоянию на сегодняшний день скорость обработки информации суперкомпьютерами стремительно опережает пропускную способность интерфейсов ввода-вывода. Графические кластеры становятся лишними. Моделирование взрыва звезды с помощью Intrepid – суперкомпьютера IBM Blue Gene/P Исследователи из Аргоннской национальной лаборатории (Argonne National Laboratory) и некоторых других организаций работают над решением проблемы. Вместо перемещения массивов данных в специализированные графические кластеры для рендеринга, как это происходит сейчас, они заняты созданием программного обеспечения, позволяющего тысячам процессоров самостоятельно выполнять визуализацию. Том Петерка (Tom Peterka) и Роб Росс (Rob Ross), ученые по компьютерным наукам Аргоннской лаборатории, и Хонгфенг Ю (Hongfeng Yu) с Кван-Лью Ма (Kwan-Liu Ma) из Калифорнийского университета в Дэвисе написали ПО для Intrepid – суперкомпьютера IBM Blue Gene/P, всецело превосходящего графические кластеры. "Он позволяет визуализировать эксперименты на той же машине, где расположены данные", - объясняет Петерка. Его решение устраняет отнимающий большое количество времени этап "переброски" данных из той машины, где они генерируются, к кластеру для обработки. Тестовые данные, которые Петерка получил от Джона Блондина (John Blondin) из Университета Северной Каролины (North Carolina State University) и Энтони Меззакаппа (Anthony Mezzacappa) из Национальной лаборатории Оак-Ридж (Oak Ridge National Laboratory), представляют 30 последовательных шагов в симуляции взрыва умирающей звезды и соответствуют типу производимых суперкомпьютером в Аргоннской лаборатории вычислений. Самый ресурсоемкий тест включал визуализацию с трехмерным разрешением 89 млрд вокселей (трехмерных пикселей), а результат в виде двухмерного изображения имел 4096 х 4096 пикселей. Вычисления задействовали 32768 ядер из имеющихся у Intrepid 163840. Двухмерные снимки сгенерированы с помощью алгоритма параллельного объемного рендеринга – классического метода преобразования трехмерных моделей. Обычно визуализация и последующая обработка сгенерированных данных Intrepid, который с 557 Тфлопс находится на 7 месте в первой десятке быстрейших суперкомпьютеров, требует отдельной графической станции – Eureka. Построенная на NVIDIA Quadro Plex S4 GPU, Eureka может похвастаться производительностью в 111 Тфлопс. Однако, по словам Петерки, "чем более производительны системы, тем большие проблемы исходят от ограниченных скоростей интерфейсов ввода-вывода". Только запись на дисковый массив сопровождающих моделирование данных на суперкомпьютере с измеряемой в петафлопсах производительностью займет непомерно длительный промежуток времени. Это несоответствие означает, что будущие суперкомпьютерные центры просто не смогут позволить себе заниматься переносом данных на графические станции и обработкой на них информации. "Для масштабов петавычислений они слишком малоэффективны", - говорит инженер компьютерных систем и эксперт по визуализации в Национальной лаборатории Лоуренса в Беркли (Lawrence Berkeley National Laboratory) Хэнк Чайлдс (Hank Childs). Чайлдс отмечает, что отдельный кластер для визуализации, такой как Eureka, обычно стоит более $1 млн, но в будущем стоимость может вырасти в 20 раз. Пэт МакКормик (Pat McCormick), работающий с самым быстрым суперкомпьютером в мире, которым на данный момент является построенная на AMD Opteron и IBM Cell машина Roadrunner в Лос-Аламосской национальной лаборатории (Los Alamos National Laboratory), объясняет, что работа Петерки над прямой визуализацией данных имеет критический характер, потому как "эти машины стали настолько большими, что выбора попросту не остается". Невозможно просто подключить один кластер к другому, имеющему нужную функциональность. Он считает дальнейшее существование основанных на графических чипах методов визуализации целесообразным лишь для некоторых типов моделирования. Петерка, МакКормик и Чайлдс воображают будущее, где суперкомпьютеры будут выполнять все вычисления на месте, с параллельной визуализацией обрабатываемых данных, а не постфактум. Чайлдс поясняет: "Идея заключается в полном избавлении от I/O–операций. Ничего не нужно записывать на носители; вы запускаете процедуры визуализации, указываете им на код для симуляции и тут же получаете изображение". Впрочем, не так легок этот путь. Прежде всего, не менее секунды займет рендеринг каждого кадра, препятствуя возможности взаимодействия с трехмерными моделями в натуральную величину. Кроме того, такой метод работы потребует очень много ресурсов самых дорогостоящих мэйнфреймов. "Суперкомпьютеры – чрезвычайно ресурсоемкие машины", - признает Чайлдс. Поскольку обычные ПК следуют за суперкомпьютерами и графическими станциями в мир многоядерных и параллельных вычислений, Петерка размышляет над уходом индустрии от специализации процессоров. AMD уже представила библиотеку OpenCL, которая делает возможным запуск разработанного для GPU кода на любом х86-совместимом чипе, и наоборот. Ксавье Кэвин (Xavier Cavin), основатель и исполнительный директор Scalable Graphics - компании-разработчика программного обеспечения для используемых бизнесом станций на базе графических чипов, - отмечает, что первый настоящий алгоритм параллельного объемного рендеринга был запущен на процессорных суперкомпьютерах, после чего "люди начали использовать GPU–кластеры для той же цели. Теперь наблюдается возвращение обратно к процессорам. Круг замыкается".
|

